
⭐️ Redisinsight 界面安装
🏢 官方地址: https://redis.io/docs/latest/operate/redisinsight/install/
⭐️ Redis字符串操作
SET/GET 设置/读取数据
redis数据是以键值对形式存储,使用 set可以设置一个键值对,set [key] [value] 输出 ok表示设置成功
> set name tanc
"OK"
使用 get [key] 来获取
> get name
"tanc"
⚠️ 注意 redis中的 key 是区分大小写的
> set Name baixie
"OK"
> get name
"tanc"
> get Name
"baixie"
还有一种就是只有在 key不存在的情况下才会设置键值对 SETNX,这里0表示没有设置成功1表示成功
> SETNX name baixie
(integer) 0
> SETNX age 18
(integer) 1
EXISTS 判断键是否存在
> EXISTS name
(integer) 1
> EXISTS bai
(integer) 0
>
KEYS 查看存在的所有键
使用通配符 * 来表示匹配所有,也就是 KEYS后面是接匹配项
> KEYS *
1) "view:video:4"
2) "age"
3) "name"
4) "view"
5) "rank:daily"
6) "Name"
//以me结尾的key
> KEYS *me
1) "name"
2) "Name"
//以a开头的key
> KEYS a*
1) "age"
Redis中文显示问题
在 redis中存储都是存储的字符串形式,是以二进制形式存储,在存储中文的时候使用 get会显示二进制
> SET TODAY "美好的一天"
"OK"
> GET TODAY
"\xe7\xbe\x8e\xe5\xa5\xbd\xe7\x9a\x84\xe4\xb8\x80\xe5\xa4\xa9"
解决办法就是在链接 redis或者使用 cli的时候加上参数 --raw即可
root@f42ae800926f:/data# redis-cli --raw
127.0.0.1:6379> GET TODAY
美好的一天
设置TTL时间
可以使用 TTL来查看 key是否设置了过期时间/剩余多久过期,超过过期时间的 key会变成 nil
// -1表示为未设置过期时间
> TTL TODAY
(integer) -1
// 表示还有8秒过期
> TTL TODAY
(integer) 8
// 表示已经过期
> TTL TODAY
(integer) -2
//查看超过的过期时间
> GET TODAY
(nil)
通过 EXPIRE 来为已存在的 key设置过期时间
> EXPIRE TODAY 10
(integer) 1EXPIRE TODAY 10
如果要创建 KEY时直接加上过期时间使用 SETEX和 PSETEX,前者为秒后者为毫秒
//SETEX
> SETEX you 10 your
"OK"
> TTL you
(integer) 6
> TTL you
(integer) 5
> TTL you
(integer) 5
> TTL you
(integer) 4
//PSETEX
> PSETEX me 1000 my
"OK"
APPEND 追加Value
在原有的 value后面追加 value,就是拼接字符串,但是如果 key不存在则是创建操作
> APPEND name baixie
(integer) 10
> GET name
"tancbaixie"
> APPEND TC me
(integer) 2
> get TC
"me"
SETRANGE 偏移量覆盖value
从偏移量 offset开始 ⽤value字符串覆盖键 key存储的原字符串。offset从0开始
> SETRANGE name 4 "ttttt"
(integer) 10
> GET name
"tanctttttt"
GETRANGE 指定范围返回字符串
返回键 key存储的字符串的从 start到 end之间(包括 start和 end)的部分
> GETRANGE name 0 3
"tanc"
INCR/DECR 加一/减一
1.将键 key存储的数字值 value加⼀/减⼀
2.若 key不存在则值先初始化为 0再加⼀/减⼀
> INCR ONE
(integer) 1
> INCR ONE
(integer) 2
> INCR ONE
(integer) 3
> DECR ONE
(integer) 2
> DECR ONE
(integer) 1
INCRBY/DECRBY 指定添加/减少
和 INCR DECR 使用方法类似
> INCRBY ONE 10
(integer) 11
> INCRBY ONE 10
(integer) 21
> DECRBY ONE 10
(integer) 11
> DECRBY ONE 10
(integer) 1
INCRBYFLOAT 浮点数的增减
> INCRBYFLOAT float 10
"10"
> INCRBYFLOAT float 10
"20"
> INCRBYFLOAT float 10.5
"30.5"
> INCRBYFLOAT float 10.5
"41
MSET/MGET/MSETNX 多个值
> MSET A a B b C c
"OK"
> MGET A B C
1) "a"
2) "b"
3) "c"
DEL 删除
> DEL A B C
(integer) 3
> MGET A B C
1) "null"
2) "null"
3) "null"
STRLEN 获取value长度
> STRLEN name
(integer) 10
FLUSHALL 删除所有键值对
> FLUSHALL
"OK"
> KEYS *
(empty list or set)
⭐️Redis 列表(list)操作
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 2的32次幂 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
LPUSH/LPUSHX 添加到列表表头
如果列表 key存在但不是列表类型,则返回错误
这两个的区别就在于 LPUSHX 当且仅当 key存在并且是⼀个列表的时候,才执 ⾏LPUSH操作
> LPUSH color red bule black
(integer) 3
> LPUSHX name xm xh xb
(integer) 0
LRANGE 查看列表value
//-1表示最后一个元素,0表示第一个
> LRANGE color 0 -1
1) "black"
2) "bule"
3) "red"
RPUSH/RPUSHX 添加到列表表尾
如果列表 key存在但不是列表类型,则返回错误
> RPUSH color yellow green
(integer) 5
> LRANGE color 0 -1
1) "black"
2) "bule"
3) "red"
4) "yellow"
5) "green"
LPOP/RPOP 弹出表头/表尾
如果列表 key不存在,则返回 nil。
// 弹出表头
> LPOP color
"black"
> LRANGE color 0 -1
1) "bule"
2) "red"
3) "yellow"
4) "green"
//弹出表尾
> RPOP color
"green"
> LRANGE color 0 -1
1) "bule"
2) "red"
3) "yellow"
RPOPLPUSH 将列表尾部迁移
如果列表 key存在但不是列表类型,则返回错误
> LRANGE color 0 -1
1) "bule"
2) "red"
3) "yellow"
> RPOPLPUSH color c
"yellow"
> LRANGE c 0 -1
1) "yellow"
LREM 移除指定元素
移除列表 key中与 element相等的 count个元素,返回被移除的元素的数量
> LRANGE name 0 -1
1) "xb"
2) "xh"
3) "xm"
> LREM name 3 xm
(integer) 1
LLEN列表长度
> LLEN color
(integer) 2
LINDEX 通过索引查找
> LLEN color
(integer) 2
> LINDEX color 1
"red"
> LINDEX color 2
(nil)
LINSERT 通过指定元素之前/之后插入元素
LINSERT key BEFORE|AFTER pivot element 将元素element插⼊到列表key中,位于pivot之前(BEFORE)或者之后(AFTER)。
> LRANGE name 0 -1
1) "xb"
2) "xh"
//之前
> LINSERT name BEFORE xh xp
(integer) 3
//之后
> LINSERT name AFTER xh xm
(integer) 4
> LRANGE name 0 -1
1) "xb"
2) "xp"
3) "xh"
4) "xm"
LSET 通过索引替换元素
LSET key index element 将列表 key中索引为 index的元素设置为 element。
> LSET name 3 xg
"OK"
> LRANGE name 0 -1
1) "xb"
2) "xp"
3) "xh"
4) "xg"
LTRIM 只保留指定 index范围内的元素
> LRANGE name 0 -1
1) "xb"
2) "xp"
3) "xh"
4) "xg"
//保留索引0-2的元素
> LTRIM name 0 2
"OK"
> LRANGE name 0 -1
1) "xb"
2) "xp"
3) "xh"
BLPOP/BRPOP 列表阻塞式(Blocking)弹出
如果当列表中没有任何元素时阻塞,直到超时或发现新的可弹出元素为⽌,LPOP/BRPOP的阻塞版本,
//BLPOP
> BLPOP c 100
1) "c"
2) "yellow"
> BLPOP list1 100
(nil)
//BRPOP
> LRANGE color 0 -1
1) "bule"
2) "red"
> BRPOP color 100
1) "color"
2) "red"
> BRPOP color 100
1) "color"
2) "bule"
> BRPOP color 100
Executing command...
BRPOPLPUSH 阻塞尾部迁移
是RPOPLPUSH的阻塞版本,当列表source中没有任何元素时阻塞,直到超时或发现新的可弹出元素为⽌
> BRPOPLPUSH name n 100
"xh"
> BRPOPLPUSH name n 100
"xp"
> BRPOPLPUSH name n 100
"xb"
> BRPOPLPUSH name n 100
Executing command...
⭐️ Redis set操作
集合和列表的区别就在于,集合内的元素时不可以重复的
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
集合对象的编码可以是 intset 或者 hashtable。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 2的32次幂 - 1 (4294967295, 每个集合可存储40多亿个成员)
SADD 添加 value到集合
> SADD color bule
(integer) 1
//查看集合内元素
> SMEMBERS color
1) "bule"
SISMEMBER 判断集合中是否存在此元素
//返回1表示存在0表示不存在
> SISMEMBER color bule
(integer) 1
> SISMEMBER color red
(integer) 0
SPOP 随机删除集合中指定个数元素
> SMEMBERS color
1) "bule"
2) "red"
3) "green"
//指定删除color集合中1个元素
> SPOP color 1
1) "bule"
> SPOP color 2
1) "red"
2) "green"
> SMEMBERS color
(empty list or set)
>
SRANDMEMBER 随机返回集合中的一个元素
> SMEMBERS color
1) "red"
2) "green"
3) "bule"
> SRANDMEMBER color 2
1) "green"
2) "bule"
> SRANDMEMBER color 1
1) "green"
> SRANDMEMBER color 1
1) "red"
>
SMOVE 移动指定元素到另外一个集合
//从color 移动到 c
> SMOVE color c red
(integer) 1
> SMOVE color c green
(integer) 1
> SMEMBERS c
1) "red"
2) "green"
SCARD 返回集合中元素的数量
> SCARD color
(integer) 1
> SCARD c
(integer) 2
SINTER 返回多个集合的交集
> SMEMBERS color
1) "bule"
2) "red"
3) "green"
> SMEMBERS c
1) "red"
2) "green"
//返回交集
> SINTER c color
1) "red"
2) "green
SINTERSTORE 两个集合的交集覆盖
和 SINTER 一样处理交集 SINTERSTORE会保存结果集到 destination集合中,⽽不是单纯返回。 若 destination存在则将其覆盖,destination可以是key本身
> KEYS *
1) "c"
2) "color"
> SMEMBERS c
1) "red"
2) "green"
> SMEMBERS color
1) "bule"
2) "red"
3) "green"
//将color和c的交集复制到color
> SINTERSTORE color color c
(integer) 2
> SMEMBERS color
1) "red"
2) "green"
SUNION 返回多个集合的并集
> SMEMBERS c
1) "bule"
2) "red"
3) "green"
4) "yellow"
> SMEMBERS color
1) "bule"
2) "red"
3) "green"
//返回并集
> SUNION c color
1) "bule"
2) "red"
3) "green"
4) "yellow"
SUNIONSTORE 两个集合的并集覆盖
和 SUNION 一样处理并集 SUNIONSTORE会保存结果集到 destination集合中,⽽不是单纯返回。 若 destination存在则将其覆盖,destination可以是key本身
> SMEMBERS color
1) "red"
2) "green"
> SMEMBERS c
1) "red"
2) "green"
3) "bule"
4) "yellow"
//将color和c的并集覆盖掉color
> SUNIONSTORE color c color
(integer) 4
> SMEMBERS color
1) "red"
2) "green"
3) "bule"
4) "yellow"
SDIFF 放回多个集合的差集
> SMEMBERS c
1) "bule"
2) "red"
3) "green"
4) "yellow"
> SMEMBERS color
1) "bule"
2) "red"
3) "green"
4) "yellow"
5) "violet"
//注意差集是由顺序的,c - color c内有4个元素而color有5个
> SDIFF c color
(empty list or set)
> SDIFF color c
1) "violet"
SDIFFSTORE 两个集合的差集覆盖
> SDIFFSTORE c color c
(integer) 1
> SMEMBERS c
1) "violet"
⭐️ Redis 有序集合(SortedSets)操作
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2的32次幂 - 1 (4294967295, 每个集合可存储40多亿个成员)。
ZADD 添加value到有序集合
有序集合的每一个 value都会和一个分数 score进行绑定,这个分数是用于排名,
> ZADD University 640 ZhonNanDX 630 HuNanDX 620 HuNanSFDX 510 JiShouDX
(integer) 4
ZRANGE 查看有序集合元素
默认是从小到大排序
> ZRANGE University 0 -1
1) "JiShouDX"
2) "HuNanSFDX"
3) "HuNanDX"
4) "ZhonNanDX"
//返回分数
> ZRANGE University 0 -1 WITHSCORES
1) "JiShouDX"
2) "510"
3) "HuNanSFDX"
4) "620"
5) "HuNanDX"
6) "630"
7) "ZhonNanDX"
8) "640"
ZSCORE 查看当个元素的分数
> ZSCORE University JiShouDX
"510"
ZINCRBY 增加某个元素分数
"上调分数线"
> ZINCRBY University 10 JiShouDX
"520"
ZCARD 返回集合中的元素个数
> ZCARD University
(integer) 4
ZCOUNT 指定分数范围查看元素个数
> ZCOUNT University 600 650
(integer) 3
ZREVRANGE 从大到小排列
> ZREVRANGE University 0 -1 WITHSCORES
1) "ZhonNanDX"
2) "640"
3) "HuNanDX"
4) "630"
5) "HuNanSFDX"
6) "620"
7) "JiShouDX"
8) "520"
ZREVRANGEBYSCORE 指定分数范围查看元素(从大到小)
//查看600~650分的大学
> ZREVRANGEBYSCORE University 650 600 WITHSCORES
1) "ZhonNanDX"
2) "640"
3) "HuNanDX"
4) "630"
5) "HuNanSFDX"
6) "620"
ZRANGEBYSCORE 指定分数范围查看元素(从小到大)
//查看600~650分的大学,注意最大分数和最小分数的填写顺序
> ZRANGEBYSCORE University 600 650 WITHSCORES
1) "HuNanSFDX"
2) "620"
3) "HuNanDX"
4) "630"
5) "ZhonNanDX"
6) "640"
ZRANK 返回指定元素的排名(从小到大)
> ZRANK University JiShouDX
(integer) 0
ZREVRANK 返回指定元素的排名(从大到小)
> ZREVRANK University JiShouDX
(integer) 3
ZREM/ZREMRANGEBYRANK/ZREMRANGEBYSCORE/ZREMRANGEBYLEX 移除有序列表的元素
ZREM将⼀个或多个成员从集合 key中移除。不存在的 member成员将被忽略
ZREMRANGEBYRANK移除有序集合 key中指定排名区间内的所有 member。(按照 score从⼩到⼤排列)
ZREMRANGEBYSCORE移除有序集合 key中指定分数区间内的所有 member。(按照 score从小到大排列)
ZREMRANGEBYLEX 移除有序集合 key中指定字典序区间内的所有 member。(按照 字典序从大到小排列)
//移除指定元素
> ZREM University JiShouDX
(integer) 1
> ZREVRANGE University 0 -1
1) "ZhonNanDX"
2) "HuNanDX"
3) "HuNanSFDX"
//移除现在从小到大第一个元素
> ZREMRANGEBYRANK University 0 0
(integer) 1
> ZREVRANGE University 0 -1
1) "ZhonNanDX"
2) "HuNanDX"
//移除600到630分数内的元素
> ZREMRANGEBYSCORE University 600 630
(integer) 1
> ZREVRANGE University 0 -1
1) "ZhonNanDX"
//移除字典序元素
> ZREMRANGEBYLEX University [ZhonNanDX [ZhonNanDX
(integer) 1
> ZREVRANGE University 0 -1
(empty list or set)
ZSCAN 增量迭代
ZUNIONSTORE/ZINTERSTORE
ZUNIONSTORE返回⼀个或多个有序集合的并集,并存储到 destination中。
ZINTERSTORE返回⼀个或多个有序集合的交集,并存储到 destination中。
⭐️ Redis HASHES操作
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Redis 中每个 hash 可以存储 2的32次幂 - 1 键值对(40多亿)
HSET/HSETNX 将键值对添加到哈希表
HSETNX 当字段不存在于这个键的时候才会添加
127.0.0.1:6379> HSET person name tanc age 18 sex male
3
//修改年龄
127.0.0.1:6379> HSET person age 21
0
127.0.0.1:6379> HGET person age
21
//使用HSETNX,由于name已经存在所以并不会发生改变
127.0.0.1:6379> HSETNX person name tan
0
127.0.0.1:6379> HGET person name
tanc
//添加不存在的
127.0.0.1:6379> HSETNX person like badminton
1
127.0.0.1:6379> HGET person like
badminton
HGET/HMGET 返回指定字段一个/多个的值
127.0.0.1:6379> HGET person like
badminton
//多个
127.0.0.1:6379> HMGET person name age sex
tanc
22
male
HEXISTS 判断字段是否存在
//存在
127.0.0.1:6379> HEXISTS person like
1
//不存在
127.0.0.1:6379> HEXISTS person school
0
HLEN 返回哈希表key字段数量
127.0.0.1:6379> HLEN person
4
HSTRLEN 返回字段值的长度
127.0.0.1:6379> HSTRLEN person age
2
127.0.0.1:6379> HSTRLEN person like
9
HINCRBY 字段值增量
Redis Hincrby 命令用于为哈希表中的字段值加上指定增量值。
增量也可以为负数,相当于对指定字段进行减法操作。
如果哈希表的 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。
如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。
对一个储存字符串值的字段执行 HINCRBY 命令将造成一个错误。
本操作的值被限制在 64 位(bit)有符号数字表示之内
127.0.0.1:6379> HINCRBY person age 1
22
HINCRBYFLOAT 字段值浮点数增量
127.0.0.1:6379> HSET person height 180
1
127.0.0.1:6379> HINCRBYFLOAT person height 1.3
181.3
HKEYS 返回HASH表中的所有字段
127.0.0.1:6379> HKEYS person
name
age
sex
like
height
HVALS 返回HASH表中的所有字段值
127.0.0.1:6379> HVALS person
tanc
22
male
badminton
181.3
HGETALL 获取哈希表中所有字段和值
127.0.0.1:6379> HGETALL person
name
tanc
age
22
sex
male
like
badminton
height
181.3
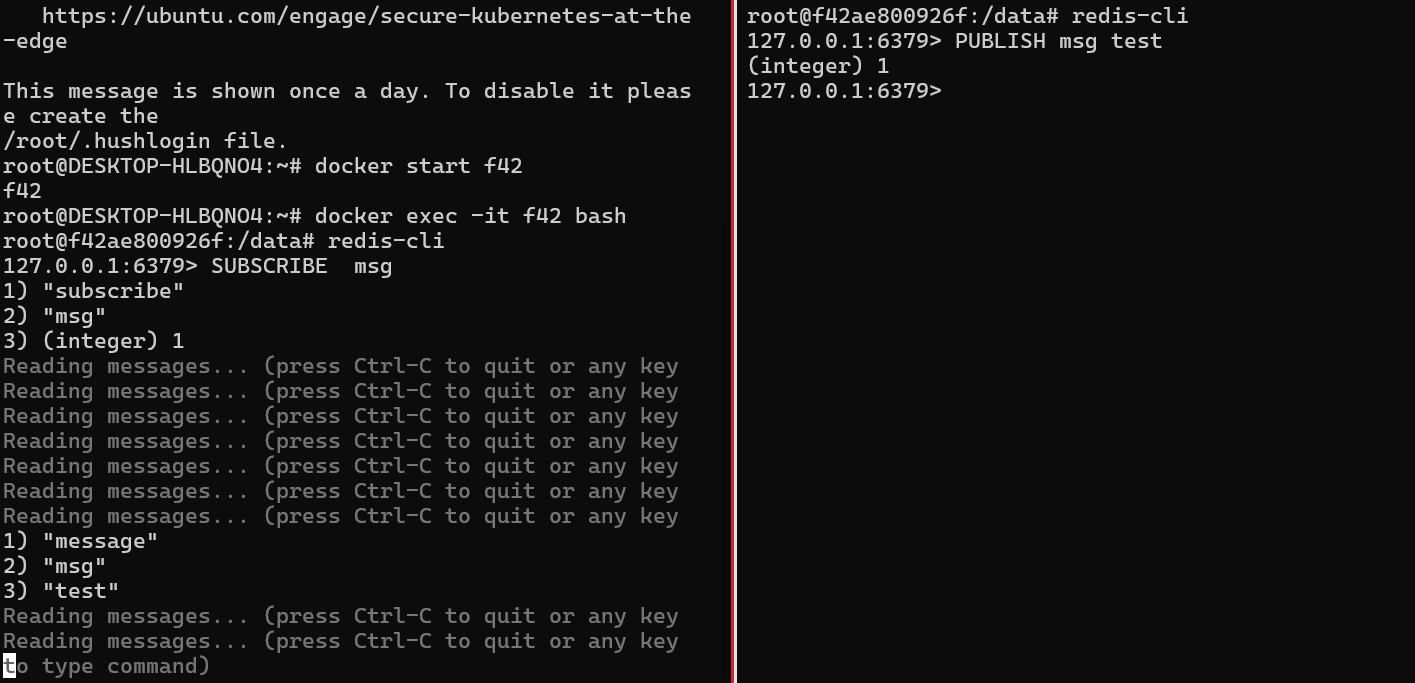
⭐️ Redis 发布订阅者模式
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis 客户端可以订阅任意数量的频道。
很像之前使用 go管道和协程写的一个及时通讯系统,这个的概念也很像 go的管道
SUBSCRIBE/PUBLISH 订阅和发送消息
⭐️ Redis stream消息队列操作
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失
XADD 添加消息到流
XADD key ID field value [field value ...]
如果 key不存在则创建
//*表示按照时间戳随机生成一个id,前面为时间戳后面为序列号
127.0.0.1:6379> XADD message * This is test stream
"1722162073959-0"
//id可以自己定义
127.0.0.1:6379> XADD test 4-1 This is test stream3
"4-1"
127.0.0.1:6379> XADD test 5-1 This is test stream3
"5-1"
XLEN 读取流中的消息数量
127.0.0.1:6379> XLEN message
(integer) 2
XTRIM 删除指定长度的消息
使用 XTRIM 对流进行修剪,限制长度, 语法格式:
XTRIM key MAXLEN [~] count
- key :队列名称
- MAXLEN :长度
- count :数量
127.0.0.1:6379> XTRIM message MAXLEN 2
(integer) 1
XREAD 读取和返回流key中⽐id⼤的消息
使用 XREAD 以阻塞或非阻塞方式获取消息列表 ,语法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
若没有则阻塞⾄消息可⽤
//查看大于id 1722162199718-0 的1条消息,如果没有则阻塞1秒
127.0.0.1:6379> XREAD COUNT 1 BLOCK 1000 STREAMS message 1722162199718-0
1) 1) "message"
2) 1) 1) "1722162200649-0"
2) 1) "This"
2) "is"
3) "test"
4) "stream3"
XINFO STREAM 查看流信息
127.0.0.1:6379> XINFO STREAM message
1) "length"
2) (integer) 2
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "last-generated-id"
8) "1722162200649-0"
9) "max-deleted-entry-id"
10) "0-0"
11) "entries-added"
12) (integer) 3
13) "recorded-first-entry-id"
14) "1722162199718-0"
15) "groups"
16) (integer) 0
17) "first-entry"
18) 1) "1722162199718-0"
2) 1) "This"
2) "is"
3) "test"
4) "stream2"
19) "last-entry"
20) 1) "1722162200649-0"
2) 1) "This"
2) "is"
3) "test"
4) "stream3"
XRANGE 返回流中指定id范围内的消息
127.0.0.1:6379> XRANGE message 1722162199718-0 1722162971047-0
1) 1) "1722162199718-0"
2) 1) "This"
2) "is"
3) "test"
4) "stream2"
2) 1) "1722162200649-0"
2) 1) "This"
2) "is"
3) "test"
4) "stream3"
3) 1) "1722162971047-0"
2) 1) "This"
2) "is"
3) "test"
4) "stream3"
XDEL 指定id删除流中消息
127.0.0.1:6379> XDEL message 1722162971047-0
(integer) 1
127.0.0.1:6379> XLEN message
(integer) 2 //原本有3个
XGROUP CREATE 创建消费者组
//message是stream的名称,后面是消费者组的名称,最后为id,这个id表示从哪跳消息开始消防,如果是$表示只从尾部开始消费,0表示从头开始
127.0.0.1:6379> XGROUP CREATE message group1 0
OK
XINFO GROUPS 查看消费者组信息
//后面需要接stream流从名称
127.0.0.1:6379> XINFO GROUPS message
1) 1) "name"
2) "group1"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "0-0"
9) "entries-read"
10) (nil)
11) "lag"
12) (nil)
XGROUP CREATECONSUMER 创建一个消费者
//最后是消费者的名字
127.0.0.1:6379> XGROUP CREATECONSUMER message group1 consumer1
(integer) 1
XINFO CONSUNER 查看消费者组内的消费者
127.0.0.1:6379> XINFO CONSUMERS message group1
1) 1) "name"
2) "consumer1"
3) "pending"
4) (integer) 0
5) "idle"
6) (integer) 2911
7) "inactive"
8) (integer) -1
XGROUP DELCONSUMER 删除消费者
//放回0表示成功
127.0.0.1:6379> XGROUP DELCONSUMER message group1 consumer1
(integer) 0
XGROUP DESTROY 删除消费者组
//放回1表示成功
127.0.0.1:6379> XGROUP DESTROY message group1
(integer) 1
XGROUP SETID 设置消费者组最后消费的id
//设置为消费1722162199718-0 后的消息
127.0.0.1:6379> XGROUP SETID message group 1722162199718-0
OK
XREADGROUP GROUP 消费消息
使用 XREADGROUP GROUP 读取消费组中的消息,语法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
// >最后这个表示从后面读取
127.0.0.1:6379> XREADGROUP GROUP group consumer2 COUNT 2 BLOCK 1000 STREAMS message >
1) 1) "message"
2) 1) 1) "1722162200649-0"
2) 1) "This"
2) "is"
3) "test"
4) "stream3"
//也可以接指定id
⭐️ Redis 地理空间
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增
GEOADD 添加一个或者多个地理位置
GEOADD key [NX|XX] [CH] longitude latitude member [longitude
latitude member ...]
这里添加了长沙,北京,深圳,广州和武汉的经纬度
127.0.0.1:6379> GEOADD city 113 28 ChangSha 116.24 39.55 BeiJing 114 23 ShenZhen 113.14 23.08 GuangZhou 114.298572 30.584355 WuHan
(integer) 5
GEODIST 计算两个地理位置之间的距离
GEODIST key member1 member2 [M|KM|FT|MI]
计算北京到广州多远
127.0.0.1:6379> GEODIST city BeiJing GuangZhou KM
"1855.0869"
127.0.0.1:6379> GEODIST city BeiJing GuangZhou M
"1855086.9223"
GEOHASH 以Hash字符串的形式返回地址位置信息
127.0.0.1:6379> GEOHASH city BeiJing
1) "wx48vpg7kq0"
127.0.0.1:6379> GEOHASH city ChangSha
1) "wsbr73hpff0"
GEOPOS 放回一个/多个地址位置的经纬度信息
127.0.0.1:6379> GEOPOS city ChangSha GuangZhou
1) 1) "112.99999862909317017"
2) "27.99999879696989069"
2) 1) "113.13999921083450317"
2) "23.08000110312545416"
GEORADIUS 指定经纬度为中间查看半径范围内的成员
##查看经纬度为0 0 半径100000公里的城市
127.0.0.1:6379> GEORADIUS city 0 0 100000 KM
1) "GuangZhou"
2) "ShenZhen"
3) "ChangSha"
4) "WuHan"
5) "BeiJing"
## 查看113 28半径400kmn内的成员
127.0.0.1:6379> GEORADIUS city 113 28 400 KM
1) "ChangSha"
2) "WuHan"
GEORADIUSBYMEMBER 指定成员为中心查看半径范围内的成员
127.0.0.1:6379> GEORADIUSBYMEMBER city BeiJing 1800 kM
1) "ChangSha"
2) "WuHan"
3) "BeiJing"
GEOSEARCH 指定范围搜索
key FROMMEMBER member|FROMLONLAT longitude latitude
BYRADIUS radius M|KM|FT|MI|BYBOX width height M|KM|FT|MI
[ASC|DESC] [COUNT count [ANY]] [WITHCOORD] [WITHDIST]
[WITHHASH]
指定范围内搜索member并返回。可以按成员(FROMMEMBER),或按经纬度(FROMLONLAT),范围可以是圆形( BYRADIUS)或矩形(BYBOX)。
ASE/DESC 为一当前用户为中心点,将数据由近到远/由远到近排序
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。
WITHCOORD: 将位置元素的经度和纬度也一并返回。
WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
COUNT 限定返回的记录数。
##按照成员
127.0.0.1:6379> GEOSEARCH city FROMMEMBER ChangSha BYRADIUS 800 KM
1) "GuangZhou"
2) "ShenZhen"
3) "ChangSha"
4) "WuHan"
##按照经纬度
127.0.0.1:6379> GEOSEARCH city FROMLONLAT 113 28 BYRADIUS 800 KM
1) "GuangZhou"
2) "ShenZhen"
3) "ChangSha"
4) "WuHan"
##按照矩形
127.0.0.1:6379> GEOSEARCH city FROMLONLAT 113 28 BYBOX 800 1000 KM
1) "ChangSha"
2) "WuHan"
GEOSEARCHSTORE 指定范围搜索并存储返回结果
GEOSEARCHSTORE destination source FROMMEMBER member|FROMLONLAT longitude latitude BYRADIUS radius M|KM|FT|MI|BYBOX width height M|KM|FT|MI
与GEOSEARCH相同,指定范围内搜索,并存储结果⾄destination。
⭐️ Redis HyperLogLog算法操作
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
他常常用于统计 UV,UV(Unique visitor):是指通过互联网访问、浏览这个网页的自然人。访问的一个电脑客户端为一个访客,一天内同一个访客仅被计算一次。
PFADD 添加一个或者多个元素到HyperLogLog
127.0.0.1:6379> PFADD course go python java docker
(integer) 1
PFCOUNT 返回HyperLogLog中的基数
127.0.0.1:6379> PFCOUNT course
(integer) 4
PFMERGE 合并多个HyperLogLog
127.0.0.1:6379> PFADD course go python java docker
(integer) 1
127.0.0.1:6379> PFCOUNT course
(integer) 4
127.0.0.1:6379> PFADD course2 git k8s
(integer) 1
##合并到course中
127.0.0.1:6379> PFMERGE course course2
OK
127.0.0.1:6379> PFCOUNT course
(integer) 6
⭐️ Redis 位图操作
bitmap就是通过最小的单位 bit来进行0或者1的设置,表示某个元素对应的值或者状态。一个 bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2。
bitmap 常用于统计用户信息比如活跃粉丝和不活跃粉丝、登录和未登录、是否打卡等
SETBIT 设置位图
##设置学习天数,0~6表示星期一到星期天,1表示学习0表示没有
127.0.0.1:6379> SETBIT study 0 1
(integer) 0
127.0.0.1:6379> SETBIT study 1 1
(integer) 0
127.0.0.1:6379> SETBIT study 2 0
(integer) 0
127.0.0.1:6379> SETBIT study 3 0
(integer) 0
127.0.0.1:6379> SETBIT study 4 0
(integer) 0
127.0.0.1:6379> SETBIT study 5 1
(integer) 0
127.0.0.1:6379> SETBIT study 6 1
(integer) 0
GETBIT 获取某个值的位
127.0.0.1:6379> GETBIT study 1
(integer) 1
127.0.0.1:6379> GETBIT study 2
(integer) 0
BITCOUNT 统计为1的数量
127.0.0.1:6379> BITCOUNT study
(integer) 4
BITPOS 返回第一个bit位
BITOP
operation destkey key [key ...]
对⼀个或者多个key进⾏位逻辑运算,并将结果存储在destkey中;
operation 可以为AND | OR | XOR | NOT
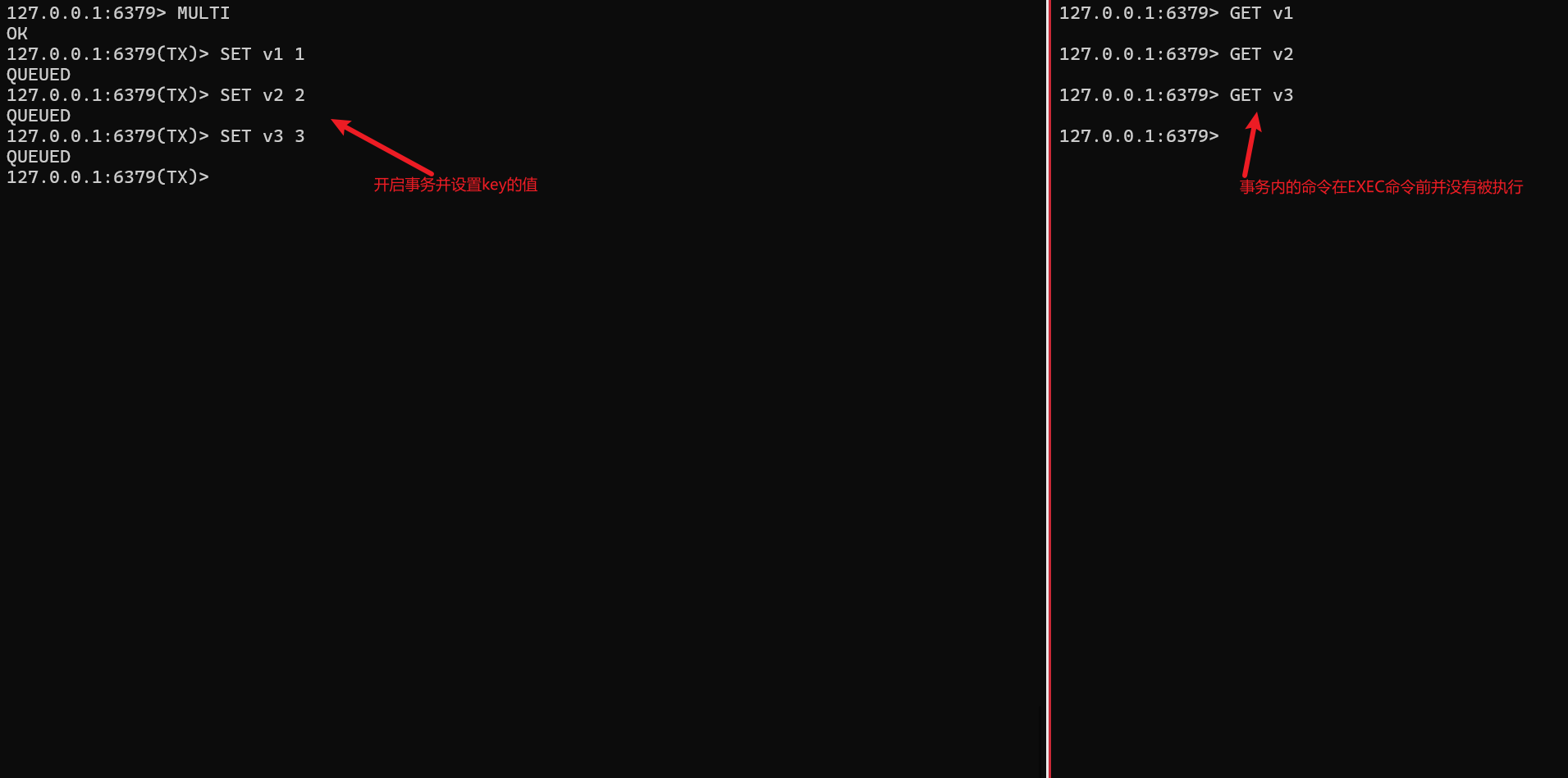
🔴 Redis 事务
1️⃣ 在redis中事务由 MULTI开启,由 EXEC命令结束
2️⃣ 在redis中事务并不能保证事务中的每个操作都成功执行,但是在 EXEC命令执行前,事务队列会先缓存起来并不会执行
3️⃣ 事务执行时,事务中任何一个命令执行失败不会立即终止而是会继续执行其他命令
4️⃣ 在当前客户端的事务执行的过程中其他客户端提交的命令请求并不会插入当前客户端的事务
##开启一个事务
127.0.0.1:6379> MULTI
OK
##这里并没有执行命令而是将命令放入队列
127.0.0.1:6379(TX)> SET v1 1
QUEUED
127.0.0.1:6379(TX)> SET v2 2
QUEUED
127.0.0.1:6379(TX)> SET v3 3
QUEUED
##开始事务,下面显示的时每个命令返回的结果
127.0.0.1:6379(TX)> EXEC
1) OK
2) OK
3) OK
##设置三个键值对其中v2为字符串
127.0.0.1:6379> SET v1 1
OK
127.0.0.1:6379> SET v2 v2
OK
127.0.0.1:6379> SET v3 3
OK
##开启事务将3个键值对都增加1
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379(TX)> INCRBY v1 1
QUEUED
127.0.0.1:6379(TX)> INCRBY v2 1
QUEUED
127.0.0.1:6379(TX)> INCRBY v3 1
QUEUED
##v2由于时字符串表示数字类中就报错了,但是他报错并不会影响其他命令的执行
127.0.0.1:6379(TX)> EXEC
1) (integer) 2
2) (error) ERR value is not an integer or out of range
3) (integer) 4
127.0.0.1:6379> GET v1
"2"
127.0.0.1:6379> GET v2
"v2"
127.0.0.1:6379> GET v3
"4"
1️⃣ RDB Redis Database 直接将内存中的数据保存到磁盘中
2️⃣ AOF Append-only file 在执行命令的同时不仅仅会将数据写入内存还会写入一个追加的文件中
开启Redis数据持久化之RDB
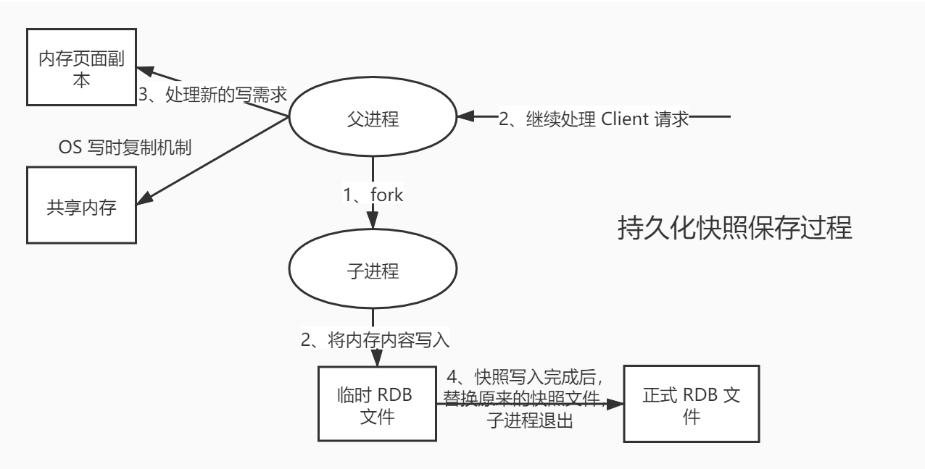
Redis 会单独创建(fork)一个子进程进行持久化,会先将数据写入一个临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程不进行任何 IO 操作,这就确保的极高的性能。如果需要大规模的数据的恢复,且对数据恢复的完整性不是非常敏感,那 RDB 方式要比 AOF 方式更加高效。RDB 唯一的缺点是最后一次持久化的数据可能会丢失。
默认持久化方式是 RDB,一般不需要修改。
rdb 保存的文件是 dump.rdb
配置RDB保存策略
## save 900 1
## save 300 10
## save 60 10000
save 60 5 ## 只要 60s 内修改了 5 次 key 就会触发 rdb 操作。
save/bgsave 手动保存RDB文件
save: 阻塞当前进程来保存
bgsave: 非阻塞 会开启一个子进程来保存
rdb文件的触发机制
触发机制
1、save 的规则满足的情况下,会自动触发 rdb 规则
2、执行 flushall 命令,也会触发 rdb 规则
3、退出 redis 也会产生 rdb 文件
备份就自动生成一个 dump.rdb 文件。
如何恢复RDB
1、只需要将 rdb 文件放在 Redis 启动目录就可以,Redis 启动的时候会自动检查 dump.rdb ,恢复其中的数据;
2、查看存放 rdb 文件的位置,在客户端中使用如下命令。
127.0.0.1:6379> config get dir
1) "dir"
2) "/usr/local/bin" ## 如果在这个目录下存在 dump.rdb 文件,启动就会自动恢复其中的数据
127.0.0.1:6379>
RDB的优缺点
RDB 的优缺点
优点:
1、适合大规模的数据恢复
2、对数据的完整性要求不高
缺点:
1、需要一定的时间间隔进行操作,如果 Redis 意外宕机,最后一次修改的数据就没有了
2、fork 进程的时候,会占用一定的空间。
AOF
AOF( append only file )持久化以独立日志的方式记录每次写命令,并在 Redis 重启时在重新执行 AOF 文件中的命令以达到恢复数据的目的。AOF 的主要作用是解决数据持久化的实时性。
以日志形式来记录每个操作,将 Redis 执行的过程的所有指令记录下来(读操作不记录),只追加文件但不可以改写文件,redis 启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一遍以完成数据的恢复工作
AOF 保存的是 appendonly.aof 文件
将配置文件中默认为 no 的 appendonly 修改为 yes ,重启服务。
appendonly no ## 默认是不开启 AOF 模式的,默认使用 rdb 方式持久化,大部分情况下,rdb 完全够用
appendfilename "appendonly.aof" ## 持久化的文件的名字
## appendfsync always ## 每次修改都会 sync 消耗性能
appendfsync everysec ## 每秒执行一次 sync 可能会丢失这 1s 的数据。
## appendfsync no ## 不执行 sync 这个时候操作系统自己同步数据,速度最快。
重启后可以看到 AOF 文件:
[root@coder bin]## ls
appendonly.aof
如果这个 AOF 文件有错位,客户端就不能链接了,需要修复 AOF 文件。Redis 提供了工具 redis-check-aof --fix
[root@coder bin]## redis-check-aof --fix appendonly.aof
0x 6e: Expected prefix '*', got: 'g'
AOF analyzed: size=122, ok_up_to=110, diff=12
This will shrink the AOF from 122 bytes, with 12 bytes, to 110 bytes
Continue? [y/N]: y
Successfully truncated AOF
[root@coder bin]##
重启服务,再次尝试链接成功。
AOF优缺点
AOF 的优缺点
appendonly yes ## 默认是 no
appendfilename "appendonly.aof" ## 持久化的文件的名字
## appendfsync always ## 每次修改都会 sync ,消耗性能
appendfsync everysec ## 每秒执行一次 sync ,可能会丢失这 1s 的数据
## appendfsync no ## 不执行 sync,这个时候操作系统自己同步数据,速度最快
优点:
1、每一次修改都同步,文件的完整性更加好
2、每秒同步一次,可能会丢失一秒的数据
3、从不同步,效率最高的
缺点:
1、相对于数据文件来说, AOF 远远大于 RDB ,修复的速度也比 RDB 慢
2、AOF 的运行效率也比 RDB 慢,所以 Redis 默认的配置就是 RDB 持久化。
问题:如果每次写命令 都保存 , set k1 v1 set k1 v2 set k1 v3 , 数据最终是v3 ,但是 每条命令都需要存储吗? 如果存储,数据恢复的时候 每条命令执行,效率是不是有影响?
aof 有 重写功能,只会保留最后一条修改的命令
拓展
1、RDB 持久化方式能够在指定的时间间隔内对你的数据进行快照存储
2、AOF 持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF 命令以Redis 协议追加保存每次写的操作到文件尾部,Redis 还能对 AOF 文件进性后台重写,使得AOF 文件的体积不至于过大(多次修改,只保留最后一次修改的命令)
3、只做缓存,如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化
4、同时开启两种持久化方式
- 在这种情况下,当 Redis 重启的时候会优先加载AOF 文件来恢复原始的数据,因为在通常情况下,AOF 文件保存的数据集要比 RDB 文件保存的数据集要完整。
- RDB 的数据不实时,同步使用两者时服务器重启也只会找 AOF 文件。那要不要只使用 AOF 呢?作者建议不要,因为 RDB 更适合用于备份数据库(AOF 在不断变化不好备份),快速重启,而且不会有 AOF 可能潜在的 BUG,留着作为一个万一的手段。
5、性能建议
- 因为 RDB 文件只用作后备用途,建议只在 Slave 上持久化 RDB 文件,而且只要 15 分钟备份一次就够了,只保留save 900 1 这条规则。
- 如果 Enable AOF ,好处是在最恶劣情况下也只会丢失不超过两秒的数据,启动脚本较简单只 load 自己的 AOF 文件就可以了,代价是一是带来了持续的IO,二是 AOF rewrite 的最后将rewrite 过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。只要硬盘许可,应该尽量减少 AOF rewrite 的频率,AOF 重写的基础大小默认值是 64M 太小了,可以设置到 5G 以上,默认值超过原大小 100% 时重写,可以改到适当的数值。
- 如果不 Enable AOF ,仅靠 Master-Slave Repllcation 实现高可用也可以,能省掉一大笔 IO ,也减少了 rewrite 时带来的系统波动。代价是如果 Master/Slave 同时宕掉,会丢失十几分钟的数据,启动脚本也要比较两个 Master/Slave 中的 RDB 文件,载入较新的那个,微博就是这种架构
🔴 Redis主从
概念
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称之为主节点(master/leader),后者称之为从节点(slave/flower);数据的复制都是单向的,只能从主节点到从节点。Master 以写为主,Slave 以读为主。
默认情况下,每台 Redis 服务器都是主节点。且一个主节点可以有多个从节点或者没有从节点,但是一个从节点只能有一个主节点
主从复制的作用
1、数据冗余:主从复制实现了数据的热备份,是持久化的之外的一种数据冗余方式。
2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复。实际也是一种服务的冗余。
3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写 Redis 数据时应用连接主节点,读 Redis 的时候应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个节点分担读负载,可以大大提高 Redis 服务器的并发量。
4、高可用(集群)的基石:除了上述作用以外,主从复制还是哨兵模式和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础。
一般来说,要将Redis 运用于工程项目中,只使用一台 Redis 是万万不能的(可能会宕机),原因如下:
1、从结构上,单个 Redis 服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力很大;
2、从容量上,单个 Redis 服务器内存容量有限,就算一台 Redis 服务器内存容量为 256G, 也不能将所有的内存用作 Redis 存储内存,一般来说,单台 Redis最大使用内存不应该超过 20G。
电商网站上的商品,一般都是一次上传,无数次浏览的,说专业点就是“读多写少”。
对于这种场景,我们可以使用如下这种架构:
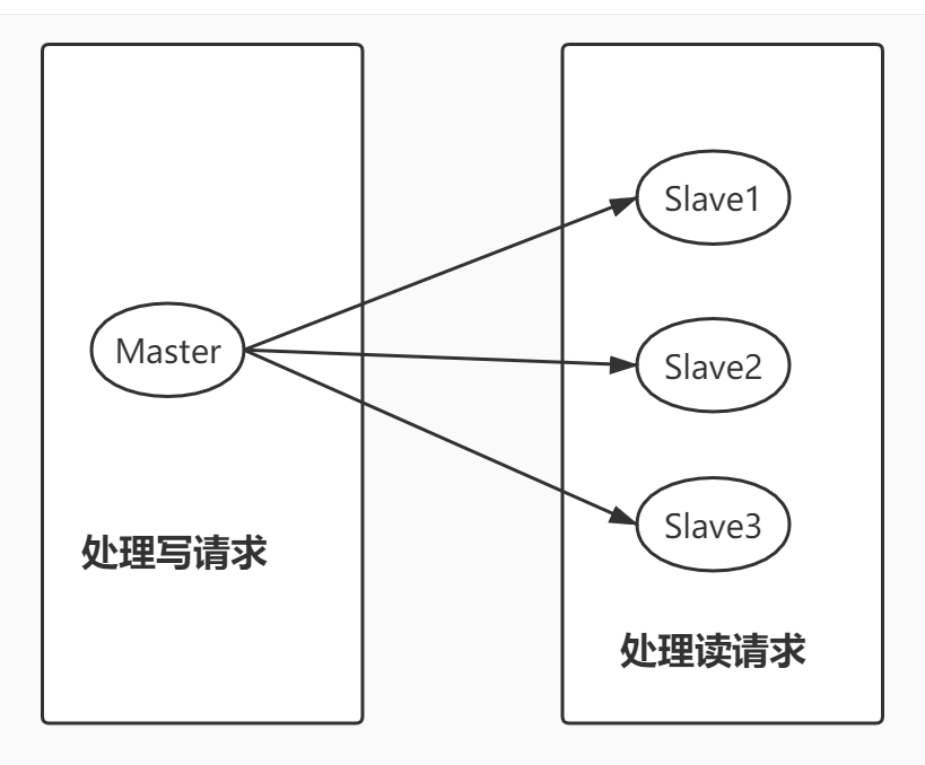
主从复制,读写分离!80% 的情况下,都是在进行读操作。这种架构可以减少服务器压力,经常使用实际生产环境中,最少是“一主二从”的配置。真实环境中不可能使用单机 Redis
部署主从
1️⃣ 部署三个redis(可以使用docker,也可以使用3台虚拟机),这里node3和node4为从节点
[root@node2 etc]# ps -ef | grep redis
root 8502 1 0 03:42 ? 00:00:18 redis-server 192.168.200.202:6379
root 9073 8469 0 07:30 pts/0 00:00:00 grep --color=auto redis
[root@node3 redis]# ps -ef | grep redis
root 3741 1 0 07:26 ? 00:00:00 redis-server 192.168.200.203:6379
root 3746 1760 0 07:27 pts/0 00:00:00 grep --color=auto redis
[root@node4 redis]# ps -ef | grep redis
root 19942 1 0 07:29 ? 00:00:00 redis-server 192.168.200.204:6379
root 19947 11492 0 07:29 pts/0 00:00:00 grep --color=auto redis
2️⃣ 在配置文件中配置主从
##在node3和node4配置从节点
##在redis.conf中添加
slaveof 192.168.200.202 6379
slave-read-only yes ##开启从节点只读
##之后需要重启3台redis
3️⃣ 查看从节点状态
192.168.200.203:6379> info replication
# Replication
role:slave ##角色为从节点
master_host:192.168.200.202 ##指出主节点
master_port:6379
master_link_status:up ##和主节点链接状态
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:98
slave_repl_offset:98
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:f6b61dc818068ba1513a7e659e5723032bace4fc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:98
4️⃣ 查看主节点
192.168.200.202:6379> info replication
# Replication
role:master ##主节点
connected_slaves:2 ##链接的从节点有两台
slave0:ip=192.168.200.203,port=6379,state=online,offset=336,lag=1
slave1:ip=192.168.200.204,port=6379,state=online,offset=336,lag=0
master_failover_state:no-failover
master_replid:f6b61dc818068ba1513a7e659e5723032bace4fc
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:336
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:336
192.168.200.202:6379>
复制原理
Slave 启动成功连接到 Master 后会发送一个 sync 同步命令。
Master 接收到命令后,启动后台的存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行完毕后,master 将传送整个数据文件到 slave ,并完成一次完全同步。
同步的数据 使用的是RDB文件,收到同步命令之后,master会bgsave 把数据保存在rdb中,发送给从机。
bgsave:fork出来一个子进程 进行处理,不影响主进程的使用。
**全量复制:**Slave 服务在接收到数据库文件后,将其存盘并加载到内存中。
增量复制: Master 继续将新的所有收集到的修改命令一次传给 slave,完成同步。
但是只要重新连接 master ,一次完全同步(全量复制)将被自动执行。我们的数据一定可以在从机中看到。

还有一种是串联 可以这样理解 node1(master)---->(slave)node2(master)---->(slave)node3

如果现在 node1节点宕机了, node2和 node3 节点都是从节点,只能进行读操作,都不会自动变为主节点。需要手动将其中一个变为主节点,使用如下命令:
SLAVEOF no one
🔴 Redis 哨兵
主从切换技术的方式是:当主机服务器宕机之后,需要手动将一台服务器切换为主服务器,这需要人工干预,费时费力,还会造成一段时间内的服务不可用。这不是一种推荐的方式,更多的时候我们优先考虑的的是哨兵模式。Redis 从 2.8 开始正式提供了 Sentinel(哨兵)架构来解决这个问题。
哨兵模式能够后台监控主机是否故障,如果故障了根据投票数(投哨兵节点)自动将从库转换为主库。
当有多个哨兵节点的时候,需要选出一个哨兵节点 来去进行主从切换。
哨兵模式是一种特殊的模式,首先 Redis 提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它独立运行。其原理是哨兵通过发送命令,等待 Redis 服务器响应,从而监控运行的多个 Redis 实例
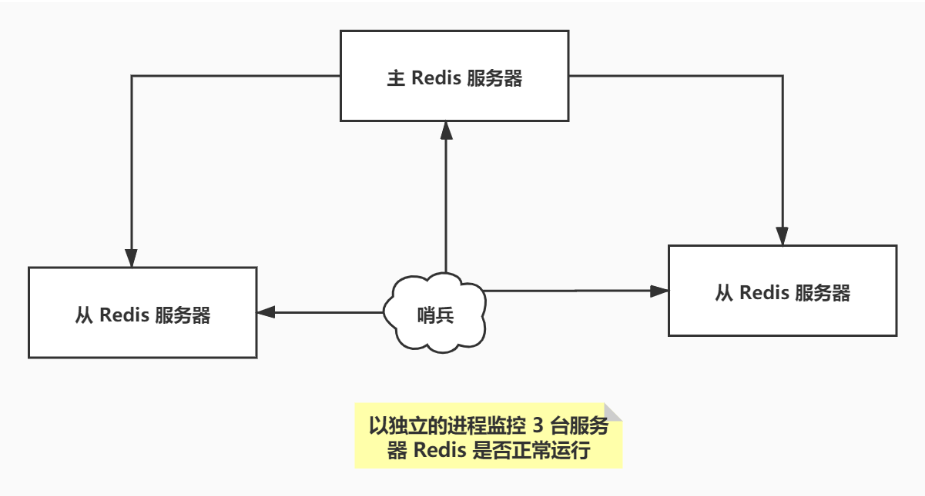
这里的哨兵有两个作用
- 通过发送命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器
- 当哨兵检测到 master 宕机,会自动将 slave 切换为 master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让他们切换主机
然而一个哨兵进程对 Redis 服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式

假设主服务器宕机了,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵 1 主观认为主服务器不可用,这个现象称之为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,这个过程称之为客观下线,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,最终会选出来一个leader(哨兵节点),进行 failover 【故障转移】。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主从切换
配置
配置说明
# sentinel实例之间的通讯端口
port 26379
# sentinel需要监控的master信息:<mastername> <masterIP> <masterPort> <quorum>。
# <quorum>应该小于集群中slave的个数,只有当至少<quorum>个sentinel实例提交"master失效" 才会认为master为ODWON("客观"失效)。
sentinel monitor mymaster 192.168.0.1 6379 2
# 授权密码,在安全的环境中可以不设置
sentinel auth-pass mymaster xxxx
# master被当前sentinel实例认定为“失效”(SDOWN)的间隔时间--秒
sentinel down-after-milliseconds mymaster 10000
# 当新master产生时,同时进行“slaveof”到新master并进行同步复制的slave个数。
#在salve执行salveof与同步时,将会终止客户端请求。 此值较大,意味着“集群”终止客户端请求的时间总和和较大。 此值较小,意味着“集群”在故障转移期间,多个salve向客户端提供服务时仍然使用旧数据。
sentinel parallel-syncs mymaster 1
# failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作,当前sentinel将会认为此次failoer失败。
sentinel failover-timeout mymaster 10000
写入配置
cat /usr/local/redis/etc/redis-sentinel.conf
port 26379
logfile /usr/local/redis/logs/redis-sentinel.log
daemonize yes
dir "/tmp"
sentinel monitor mymaster 192.168.200.202 6379 2
sentinel down-after-milliseconds mymaster 10000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 10000
##切换vip执行的脚本位置
sentinel client-reconfig-script mymaster /usr/local/redis/bin/redis_sentinel_failover.sh
启动哨兵
[root@coder bin]## ls
6379.log 6381.log dump6380.rdb dump.rdb redis-benchmark redis-check-rdb redis-sentinel
6380.log dump6379.rdb dump6381.rdb redis-config redis-check-aof redis-cli redis-server
[root@coder bin]## redis-sentinel redis-config/sentinel.conf
2421:X 15 May 2020 20:24:06.847 ## oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2421:X 15 May 2020 20:24:06.847 ## Redis version=5.0.5, bits=64, commit=00000000, modified=0, pid=2421, just started
2421:X 15 May 2020 20:24:06.847 ## Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.5 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 2421
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
2421:X 15 May 2020 20:24:06.848 ## WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
2421:X 15 May 2020 20:24:06.851 ## Sentinel ID is 100430af0018d23bd1ae2fe57e71e0d45f64d9a5
2421:X 15 May 2020 20:24:06.851 ## +monitor master myredis 127.0.0.1 6379 quorum 1
2421:X 15 May 2020 20:24:06.852 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
启动成功~!
如果现在 Master 节点宕机了,这个时候会从从机中根据投票算法选择一个作为主机。
如果原来的主机恢复运行了,只能归到新的主机下,作为从机, 这就是哨兵模式的规则。
哨兵模式的优点
1、哨兵集群,基于主从复制模式,所有的主从配置优点,它全有
2、主从可以切换,故障可以转移,系统的可用性就会更好
3、哨兵模式就是主从模式的升级,手动到自动,更加健壮。
哨兵模式的缺点
1、Redis 不方便在线扩容,集群达到一定的上限,在线扩容就会十分麻烦;
2、实现哨兵模式的配置其实也很麻烦,里面有甚多的配置项
🔴 Redis 集群
随着业务系统功能、模块、规模、复杂性的增加,我们对Redis的要求越来越高,尤其是在高低峰场景的动态伸缩能力,比如:电商平台平日流量较低且平稳,双十一大促流量是平日的数倍,两种情况下对于各系统的数量要求必然不同。如果始终配备高峰时的硬件及中间件配置,必然带来大量的资源浪费。
Redis作为业界优秀的缓存产品,成为了各类系统的必备中间件。哨兵模式虽然优秀,但由于其不具备动态水平伸缩能力,无法满足日益复杂的应用场景。在官方推出集群模式之前,业界就已经推出了各种优秀实践,比如:Codis、twemproxy等。
为了弥补这一缺陷,自3.0版本起,Redis官方推出了一种新的运行模式——Redis Cluster。
Redis Cluster采用无中心结构,具备多个节点之间自动进行数据分片的能力,支持节点动态添加与移除,可以在部分节点不可用时进行自动故障转移,确保系统高可用的一种集群化运行模式。按照官方的阐述,Redis Cluster有以下设计目标:
- 高性能可扩展,支持扩展到1000个节点。多个节点之间数据分片,采用异步复制模式完成主从同步,无代理方式完成重定向。
- 一定程度内可接受的写入安全:系统将尽可能去保留客户端通过大多数主节点所在网络分区所有的写入操作,通常情况下存在写入命令已确认却丢失的较短时间窗口。如果客户端连接至少量节点所处的网络分区,这个时间窗口可能较大。
- 可用性:如果大多数节点是可达的,并且不可达主节点至少存在一个可达的从节点,那么Redis Cluster可以在网络分区下工作。而且,如果某个主节点A无从节点,但是某些主节点B拥有多个(大于1)从节点,可以通过从节点迁移操作,把B的某个从节点转移至A。
简单概述。结合以上三个目标,我认为Redis Cluster最大的特点在于可扩展性,多个主节点通过分片机制存储所有数据,即每个主从复制结构单元管理部分key。
因为在主从复制、哨兵模式下,同样具备其他优点。
当系统容量足够大时,读请求可以通过增加从节点进行分摊压力,但是写请求只能通过主节点,这样存在以下风险点:
- 所有写入请求集中在一个Redis实例,随着请求的增加,单个主节点可能出现写入延迟。
- 每个节点都保存系统的全量数据,如果存储数据过多,执行rdb备份或aof重写时fork耗时增加,主从复制传输及数据恢复耗时增加,甚至失败;
- 如果该主节点故障,在故障转移期间可能导致所有服务短时的数据丢失或不可用。
所以,动态伸缩能力是Redis Cluster最耀眼的特色
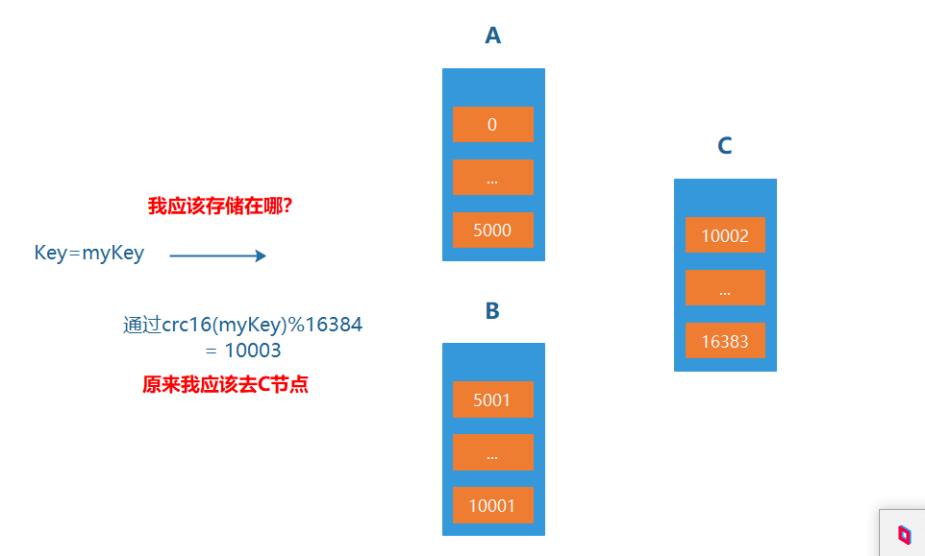
哈希槽
Redis-cluster引入了哈希槽的概念。
Redis-cluster中有16384(即2的14次方)个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽。
Cluster中的每个节点负责一部分hash槽(hash slot)。
比如集群中存在三个节点,则可能存在的一种分配如下:
- 节点A包含0到5500号哈希槽;
- 节点B包含5501到11000号哈希槽;
- 节点C包含11001 到 16383号哈希槽。
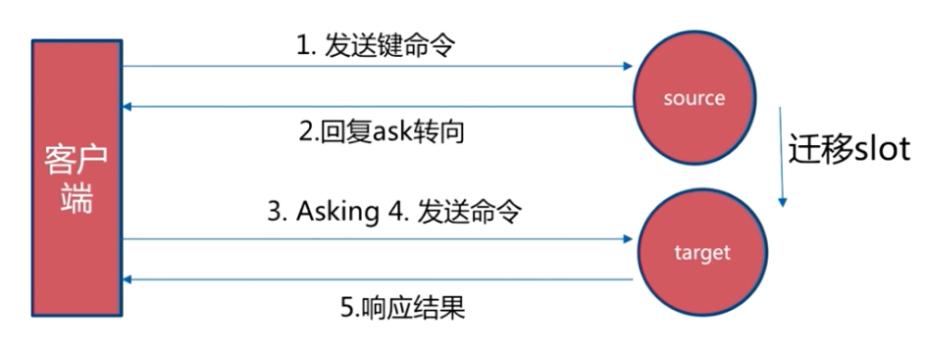
请求重定向
Redis cluster采用去中心化的架构,集群的主节点各自负责一部分槽,客户端如何确定key到底会映射到哪个节点上呢?这就是我们要讲的请求重定向。
在cluster模式下,节点对请求的处理过程如下:
- 检查当前key是否存在当前NODE?
- 通过crc16(key)/16384计算出slot
- 查询负责该slot负责的节点,得到节点指针
- 该指针与自身节点比较
- 若slot不是由自身负责,则返回MOVED重定向
- 若slot由自身负责,且key在slot中,则返回该key对应结果
- 若key不存在此slot中,检查该slot是否正在迁出(MIGRATING)?
- 若key正在迁出,返回ASK错误重定向客户端到迁移的目的服务器上
- 若Slot未迁出,检查Slot是否导入中?
- 若Slot导入中且有ASKING标记,则直接操作
- 否则返回MOVED重定向
move重定向:

- 槽命中:直接返回结果
- 槽不命中:即当前键命令所请求的键不在当前请求的节点中,则当前节点会向客户端发送一个Moved 重定向,客户端根据Moved 重定向所包含的内容找到目标节点,再一次发送命令。
ASK 重定向:
Ask重定向发生于集群伸缩时,集群伸缩会导致槽迁移,当我们去源节点访问时,此时数据已经可能已经迁移到了目标节点,使用Ask重定向来解决此种情况
Cluster集群结构搭建
搭建方式
- 配置服务器(3主3从) 2. 建立通信(Meet) 3. 分槽(Slot) 4. 搭建主从(master-slave)
Cluster配置:
- 是否启用cluster,加入cluster节点
cluster-enabled yes|no - cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-config-file filename - 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-node-timeout milliseconds - master连接的slave最小数量
cluster-migration-barrier min_slave_number
Cluster节点操作命令:
- 查看集群节点信息
cluster nodes - 更改slave指向新的master
cluster replicate master-id - 发现一个新节点,新增master
cluster meet ip:port - 忽略一个没有solt的节点
cluster forget server_id - 手动故障转移
cluster failover
redis-cli命令
-
创建集群
redis-cli –-cluster create masterhost1:masterport1 masterhost2:masterport2 masterhost3:masterport3 [masterhostn:masterportn …] slavehost1:slaveport1 slavehost2:slaveport2 slavehost3:slaveport3 ––cluster-replicas nmaster与slave的数量要匹配,一个master对应n个slave,由最后的参数n决定
master与slave的匹配顺序为第一个master与前n个slave分为一组,形成主从结构
-
添加master到当前集群中,连接时可以指定任意现有节点地址与端口
redis-cli --cluster add-node new-master-host:new-master-port now-host:now-port -
添加slave
redis-cli --cluster add-node new-slave-host:new-slave-port master-host:master-port --cluster-slave --cluster-master-id masterid -
删除节点,如果删除的节点是master,必须保障其中没有槽slot
redis-cli --cluster del-node del-slave-host:del-slave-port del-slave-id -
重新分槽,分槽是从具有槽的master中划分一部分给其他master,过程中不创建新的槽
redis-cli --cluster reshard new-master-host:new-master:port --cluster-from srcmaster-id1, src-master-id2, src-master-idn --cluster-to target-master-id --cluster-slots slots
将需要参与分槽的所有masterid不分先后顺序添加到参数中,使用,分隔
指定目标得到的槽的数量,所有的槽将平均从每个来源的master处获取
- 重新分配槽,从具有槽的master中分配指定数量的槽到另一个master中,常用于清空指定master中的槽
redis-cli --cluster reshard src-master-host:src-master-port --cluster-from srcmaster-id --cluster-to


