
📅 2025/03/02
📦 ck版本 25.1.3.23
🏆 MegerTree之分区
⭐️ 数据是以分区目录的形式进行组织的,每个分区独立分开存储。借助这种形式,在对 MergeTree进行数据查询时,可以有效跳过无用的数据文件,只使用最小的分区目录子集。这里有一点需要明确,在 ClickHouse中,数据分区(partition)和数据分片(shard)是完全不同的概念。数据分区是针对本地数据而言的,是对数据的一种纵向切分。MergeTree并不能依靠分区的特性,将一张表的数据分布到多个 ClickHouse服务节点。而横向切分是数据分片(shard)的能力
1️⃣ 数据分区的规则
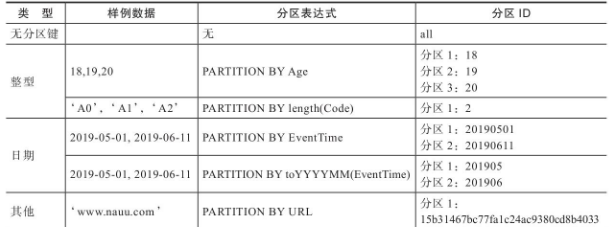
MergeTree数据分区的规则由分区ID决定,而具体到每个数据分区所对应的ID,则是由分区键的取值决定,的针对取值数据类型的不同,分区ID的生成逻辑目 前拥有四种规则
- 不指定分区键:如果不使用分区键,即不使用
PARTITIONBY声明任何分区表达式,则分区ID默认取名为all,所有的数据都会被 写入这个all分区。 - 使用整型:如果分区键取值属于整型(兼容
UInt64,包括 有符号整型和无符号整型),且无法转换为日期类型YYYYMMDD格 式,则直接按照该整型的字符形式输出,作为分区ID的取值。 - 使用日期类型:如果分区键取值属于日期类型,或者是能够 转换为
YYYYMMDD格式的整型,则使用按照YYYYMMDD进行格式化 后的字符形式输出,并作为分区ID的取值。 - 使用其他类型:如果分区键取值既不属于整型,也不属于日 期类型,例如
String、Float等,则通过128位Hash算法取其Hash值 作为分区ID的取值
⚠️ 如果使用多个分区字段,则分区
ID依旧是根据上述规则生成的,但是多个ID之通过‘-’链接比如如果分区指定了
PARTITION BY (length(Code),EventTime)那么分区id为 2-20250101
2️⃣ 分区的目录介绍
分区的目录也是有命名规则的,在 ck中完整的命名分区为如下,是由分区id_最小分区块 _最大分区块 _合并层级
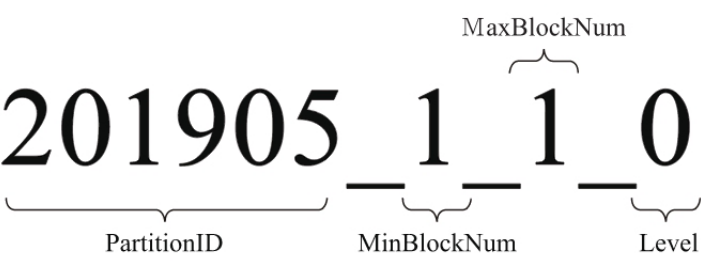
MinBlockNum和 MaxBlockNum: BlockNum是一个整型的自增长编号。如果将其设为n的话,那么计数n在单张 MergeTree数据表内全局累加,n从1开始,每 当新创建一个分区目录时,计数n就会累积加1。对于一个新的分区目录而言,MinBlockNum与 MaxBlockNum取值一样,同等于n,例如 201905_1_1_0、201906_2_2_0以此类推。但是也有例外,当分区 目录发生合并时,对于新产生的合并目录 MinBlockNum与 MaxBlockNum有着另外的取值规则
Level: 合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄。数值越高表示年龄越大。Level计数与 BlockNum有所不同,它并不是全局累加的。对于每一个新创建的分区目录而言,其初始值均为0。之后,以分区为单位,如果相同分区发生合并动作,则在相应分区内计数累积加1
3️⃣ 合并过程
在合并树种,分区并不是在数据表创建之后旧被存在的,而是在数据写入过程中被创建的,而且也是不是一成不变的,伴随着每一批数据的写入,合并树都会生成一批新的分区目录,而且即使分区也已经存在了也会生成不同分区的目录,也就是说,对于同一个分区而言,也会存在多个分区目录的情况。在之后的某个时刻,大约是写入之后的10~15分钟,会自动合并成一个新的目录,已经存在的旧分区目录在合并后并不会删除,而是在之后的某个时刻在删除
🏷 合并分区命名规则:
- MinBlockNum: 取同一分区内所有目录中最小的
MinBlockNum值。 - MaxBlockNum:取同一分区内所有目录中最大的
MaxBlockNum值。 - Level:取同一分区内最大Level值并加1
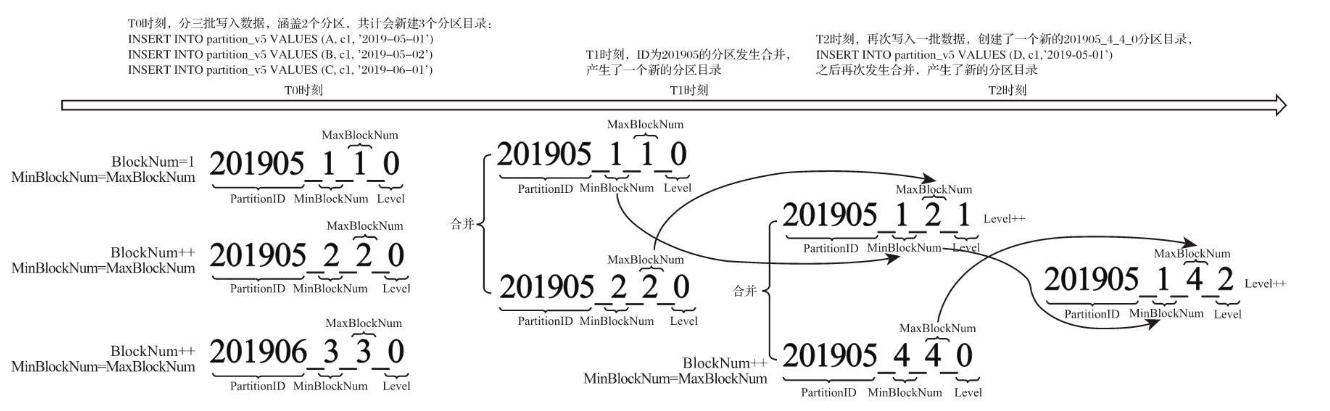
举个列子
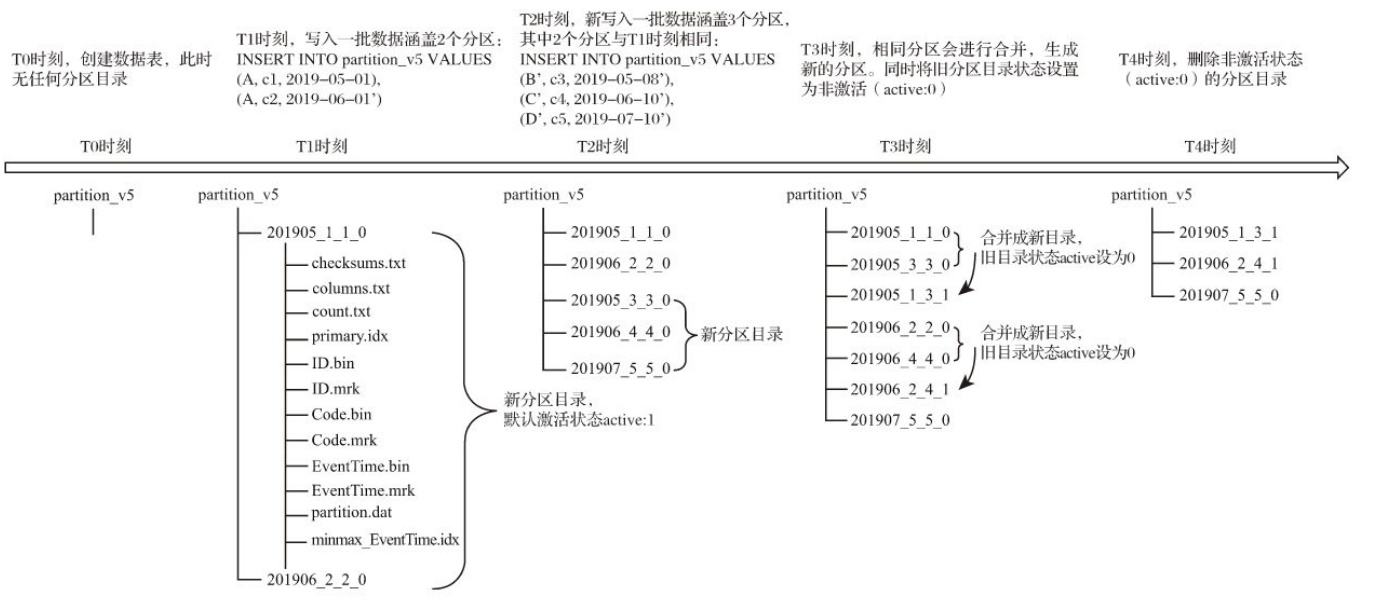
分区目录在发生合并之后,旧的分区目录并没有被立即删除,而是会存留一段时间。但是旧的分区目录已不再是激活状态(active=0),所以在数据查询时,它们会被自动过滤掉

