
📅 2025/03/12
读《clickhouse 原理解析与实践》笔记
🏆 ClickHouse 之索引
🍊 一级索引
MergeTree的主键使用 PRIMARY KEY定义,待主键定义之后, MergeTree会依据 index_granularity间隔(默认 8192行),为数据 表生成一级索引并保存至 primary.idx文件内,索引数据按照 PRIMARY KEY排序。相比使用 PRIMARY KEY定义,更为常见的简化形式是通过 ORDER BY指代主键。在此种情形下,PRIMARY KEY与 ORDER BY定义相同,所以索引(primary.idx)和数据(.bin)会按照完全相同的规则排序
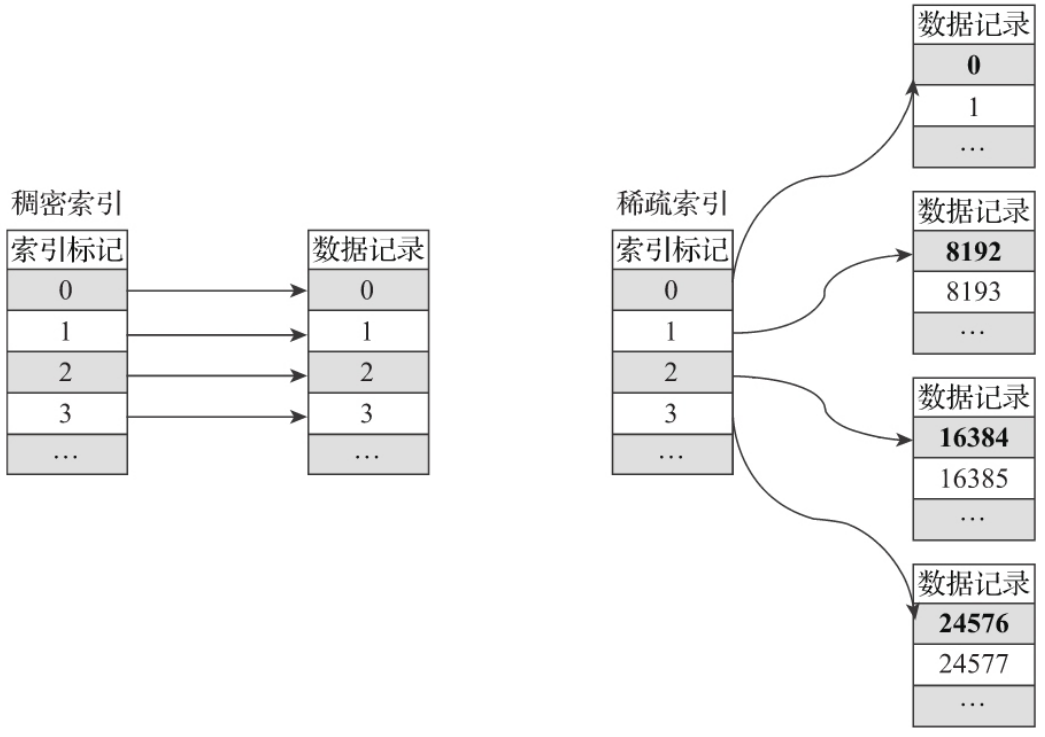
1️⃣ 稀疏索引
稀疏索引和稠密索引的区别: 在稠密索引中每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中,每一行索引标记对应的是一段数据,而不是一行。用一个形象的例子来说明:如果把MergeTree比作一本书,那么稀疏索引就好比是这本书的一级章节目录。一级章节目录不 会具体对应到每个字的位置,只会记录每个章节的起始页码
2️⃣ 索引粒度
在ck中默认的索引粒度为8192,ck还支持动态索引粒度,但是一般情况下只会用到默认的这个索引粒度
索引粒度就如同标尺一般,会丈量整个数据的长度,并依照刻度对数据进行标注,最终将数据标记成多个间隔的小段

在ck中索引将数据切割成一个一个的 MarkRange,使用start和end来表示具体的范围,前面提到过的索引文件.idx,他就是记录索引位置的,但是只单单通过.idx文件无法查咋到数据,还需要通过.mrk标记文件来定位数据
所以一级索引和数据标记的间隔粒度相同(同为 index_granularity行),彼此对齐。而数据文件也会依照 index_granularity的间隔粒度生成压缩数据块
如果初始有8192*3条数据,在没有修改默认索引粒度的情况下,产生的idx、bin、mark文件都是会按照8192索引粒度来索引,如果修改成4096,在插入8192条数据,则会生成新的idx、bin、mark文件
3️⃣ 稀疏索引的生成规则
由于是稀疏索引,所以 MergeTree需要间隔 index_granularity 行数据才会生成一条索引记录,其索引值会依据声明的主键字段获 取,举个例子,比如一个表他的分区键为 PARTITION BY toYYYYMM(EventDate) 如果是2025-03月份的数据就会分在一个分区内,并且生成.bin、.idx和.mrk文件,如果他的索引键为 ORDER BY CounterID,按照默认的8192行数据就会区一次 CounterID作为索引id写入 primary.idx文件中
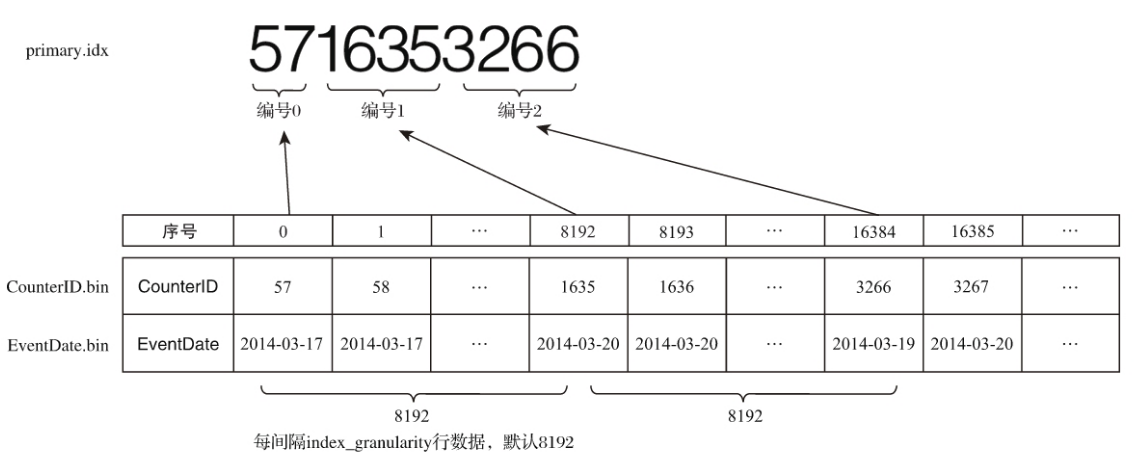
如上图区57 1637 3266存储之 primary.idx文件中,
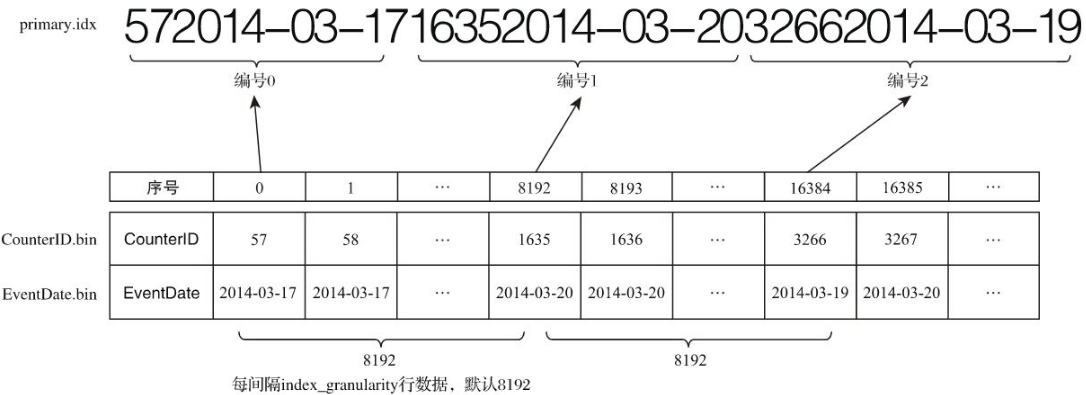
那如果有多个主键呢?比如 ORDER BY(CounterID,EventDate) 这时候就会同时取这两个键作为主键id,如下图所示
4️⃣ 索引的查询过程
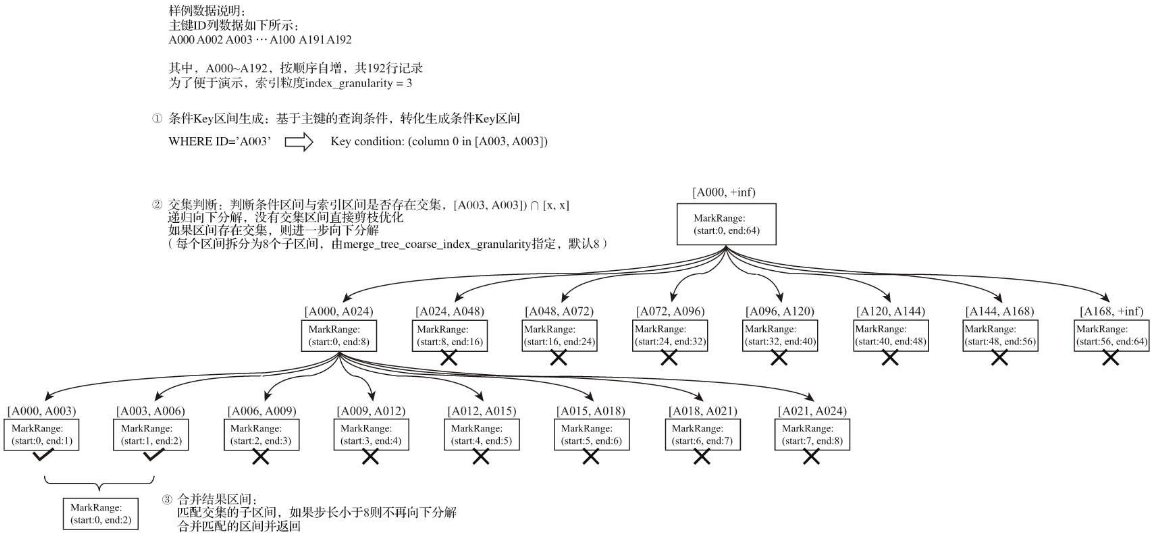
前面提到过 markrange这个概念,他将ck中的数据划分成一个一个的区间,如下图,设置的默认索引粒度为3
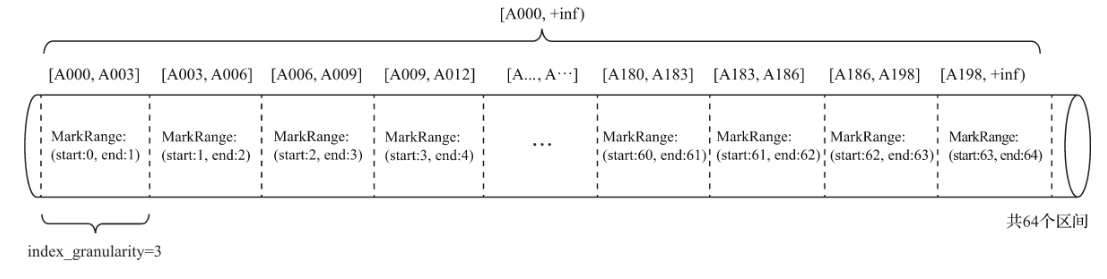
那么索引的查询就是依靠这些区间,来进行查询;
索引查询其实就是两个数值区间的交集判断。其中,一个区间是由基于主键的查询条件转换而来的条件区间;而另一个区间是刚才所讲述的与MarkRange对应的数值区间
索引的查询过程
-
通过查询条件来生成条件区间,即便是单个值的查询条件,也会被转换成区间的形式如下
WHERE ID = 'A003' ['A003', 'A003'] WHERE ID > 'A000' ('A000', +inf) WHERE ID < 'A188' (-inf, 'A188') WHERE ID LIKE 'A006%' ['A006', 'A007') -
归交集判断:以递归的形式,依次对
MarkRange的数值区间与条件区间做交集判断。从最大的区间[A000,+inf)开始在数据库查询优化中,剪枝算法用于选择可能的查询执行路径。例如,假设有多个可能的查询计划来执行某个查询,剪枝算法会评估每个计划的成本,并排除那些成本超过当前最优计划成本一定阈值的计划。动态规划中的分支定界法也属于剪枝算法,它在搜索可能的解时,设置一个边界值,一旦发现某个分支的当前解不可能优于已知的最优解,就剪掉这个分支,避免无意义的探索。
1. 如果不存在交集,则直接通过剪枝算法优化此整段 MarkRange 2. 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区间(由merge_tree_coarse_index_granularity指定,默认值为8),并重 复此规则,继续做递归交集判断 3. 如果存在交集,且MarkRange不可再分解(步长小于8),则记 录MarkRange并返回 -
合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围
如下是查询ID= ‘A003‘ 查询图示
🍐 二级索引
除了一级索引之外,
MergeTree同样支持二级索引。二级索引又称跳数索引,由数据的聚合信息构建而成。根据索引类型的不同,其聚合信息的内容也不同。跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
在最新的ck中,默认开启了二级索引
跳数索引需要在
CREATE语句内定义,它支持使用元组和表达式的形式声明,如下
CREATE TABLE table_name
(
column1 DataType,
column2 DataType,
...
INDEX index_name expr TYPE type(...) GRANULARITY granularity_value -- 这行
) ENGINE = MergeTree();
注意: 与一级索引一样,如果在建表语句中声明了跳数索引,则会额外生成相应的索引与标记文件(skp_idx_[Column].idx与 skp_idx_[Column].mrk)
1️⃣ granularity与index_granularity的关系
这是📚书上原话: 对于跳数索引而言,index_granularity定义了数据的粒度,而 granularity定义了聚合信息汇总的粒度。换言之,granularity定义了一行跳数索引能够跳过多少个 index_granularity区间的数据;
也就是说,比如 granularity 为2,index_granularity 为 8192,可以跳过2个 index_granularity ,也就是可以跳过 2 *8192 行,具体栗子🌰:

假设我们有一个表 test_table,包含以下列:
CREATE TABLE test_table ( id UInt32, value String ) ENGINE = MergeTree() ORDER BY id SETTINGS index_granularity = 8192;
index_granularity:设置为 8192,表示每个稀疏索引条目覆盖 8192 行数据。 数据量:假设表中有 100 万行数据。
数据分布: 假设数据按照 id 列的顺序存储,id 的值从 1 到 100 万。数据分布如下:
第 1 行到第 8192 行:id 从 1 到 8192
第 8193 行到第 16384 行:id 从 8193 到 16384
...
第 999993 行到第 1000000 行:id 从 999993 到 1000000
现在为 value 列创建一个跳数索引,索引类型为 set,granularity 设置为 2:
ALTER TABLE test_table ADD INDEX idx_value value TYPE set(100) GRANULARITY 2;
索引条目覆盖范围: index_granularity:每个稀疏索引条目覆盖 8192 行数据。granularity:每个跳数索引条目覆盖 2 个 index_granularity 的数据块,即 2 × 8192 = 16384 行数据。
具体来说:
第 1 个跳数索引条目覆盖 id 从 1 到 16384
第 2 个跳数索引条目覆盖 id 从 16385 到 32768
...
第 62 个跳数索引条目覆盖 id 从 999993 到 1000000
假设我们执行以下查询:
SELECT * FROM test_table WHERE value = 'some_value';
跳数索引的作用:跳数索引会根据 value 列的值快速定位到可能包含该值的数据块。
跳过无关数据块:如果某个跳数索引条目中没有包含 some_value,则可以跳过该条目覆盖的 16384 行数据,从而减少 I/O 操作和查询时间。
假设 some_value 只出现在 id 从 50000 到 60000 的数据块中:
跳数索引条目:
第 4 个跳数索引条目覆盖 id 从 32769 到 49152
第 5 个跳数索引条目覆盖 id 从 49153 到 65536
查询过程:
跳数索引会检查第 4 个和第 5 个跳数索引条目,发现第 4 个条目中没有 some_value,跳过 16384 行数据。
第 5 个跳数索引条目中包含 some_value,进一步检查该条目覆盖的 16384 行数据,最终定位到 id 从 50000 到 60000 的数据块。
2️⃣ 跳数索引的类型
MergeTree共支持4种跳数索引,分别是 minmax、set、ngrambf_v1和 tokenbf_v1。一张数据表支持同时声明多个跳数索引
CREATE TABLE skip_test
( ID String,
URL String,
Code String,
EventTime Date,
INDEX a ID TYPE minmax GRANULARITY 5,
INDEX b(length(ID) * 8) TYPE set(2) GRANULARITY 5,
INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5,
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5
) ENGINE = MergeTree() 省略...
-
minmax:minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录的minmax索引,能够快速跳过无用的数据区间 -
set:set索引直接记录了声明字段或表达式的取值(唯一值,无重复),其完整形式为set(max_rows),其中max_rows是一个阈值,表示在一个index_granularity内,索引最多记录的数据行数。如果max_rows=0,则表示无限制如果有
8192个数据且他们id都是唯一的,使用set索引指定id为二级索引,set(100) granularity 为5默认索引粒度为8192,那也就说现在就只能存储100条数据剩下的8092条数据将不会生成索引例如:
INDEX b(length(ID) * 8) TYPE set(100) GRANULARITY 5假设一个索引的
GRANULARITY=101,表示每 101 行数据划分为一个粒度单元。同时 max_rows=100,意味着在这个粒度单元内,索引最多记录 100 个不同的值,无论粒度单元有多大。
情景分析:一个粒度单元有 101 行数据。如果这些行的length(ID)*8值有 101 个唯一的值,但 max_rows=100,那么索引只会记录 100 个唯一的值。剩下的 1 个唯一的值不会被索引记录。
这样,当需要查询这个未被记录的值时,无法直接通过索引定位到数据,必须扫描整个粒度单元内的所有数据行,这会影响查询效率。
max_rows控制每个粒度单元内索引记录的唯一值数量,而不管粒度单独有多大。
如果粒度内的唯一值超过 max_rows,索引仅记录部分值,可能导致某些查询无法利用索引,需要进行全表扫描。 -
ngrambf_v1:ngrambf_v1索引记录的是数据短语的布 隆表过滤器,只支持String和FixedString数据类型。ngrambf_v1只能够提升in、notIn、like、equals和notEquals查询的性能,其完整形式为ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash _functions,random_seed) ·n:token 长度,依据 n 的长度将数据切割为 token 短语。 ·size_of_bloom_filter_in_bytes: 布隆过滤器的大小。 ·number_of_hash_functions: 布隆过滤器中使用 Hash 函数的个数。 ·random_seed: Hash 函数的随机种子例如在下面的例子中,
ngrambf_v1索引会依照3的粒度将数据切割成短语token,token会经过2个Hash函数映射后再被写入,布隆过滤器大小为256字节INDEX c(ID,Code) TYPE ngrambf_v1(3, 256, 2, 0) GRANULARITY 5 -
tokenbf_v1:tokenbf_v1索引是ngrambf_v1的变种, 同样也是一种布隆过滤器索引。tokenbf_v1除了短语token的处理方 法外,其他与ngrambf_v1是完全一样的。tokenbf_v1会自动按照非字符的、数字的字符串分割token
INDEX d ID TYPE tokenbf_v1(256, 2, 0) GRANULARITY 5

